最近在群裡有個朋友問了個問題是這樣的
用户表有一千多万行,主键是用户ID,我做了分区。但经常查询时,其它的表根据用户ID来关联,这样跨区查询,reads非常高。有什么好的处理办法?不分区的话,索引维护要好久的时间
在查看了他提供的分區資訊後,發現只有23個分區(包含一定要有的Null分區)
Null分區在這裡的定義其實很簡單,當你的資料沒有辦法放到你先前建立的分區時,就會將該資料放到所謂的Null分區(預設分區)。
因此如果在探尋分區規則時沒有依照現有的資料進行分區的設計,將會很容易導致,一但資料出現了偏斜時在查找時就會很容易在NULL區出現過多的讀取
以今天的案例來看待,當要比對的ID不在這22個分區中時就會到NULL分區進行查找的動作。而在群友提供的資料中其實有出現了oGpI0w_ 、mGpI0w等字眼
可以想見的是,該NULL分區的資料是相當多的
以下就一個測試情境來探討在分區規則不同時的效能比較
首先建立二張結構一樣的表,資料量約一千二百萬筆
接下來分別建立給表Demo1與Demo2的表分區函數(請注意圖中的註解)(注意,以下示範並沒有利用到分區FileGroup優化,當你用了分區時請一定要同時利用FileGroup進行優化)
一個是利用UserID前五碼分區另一個則利用前一碼進行分區
這裡要注意的是SQL Server 2016一個資料表或索引最多可以有 15,000 個資料分割
SQL Server 2005 與 2008 則需為SP2才可使用 (否則只能合計有1000個分區)
Refer :
Demo1表分區函數
Demo2表分區函數
而在表中不重複前五碼的資料筆數約9百多萬,如下圖 (可以想見的是在NULL區中會有大量的資料存放)
接下來我們來看看分區後的Demo1與Demo2分區表資料分佈情形

Demo1表分區資料分佈
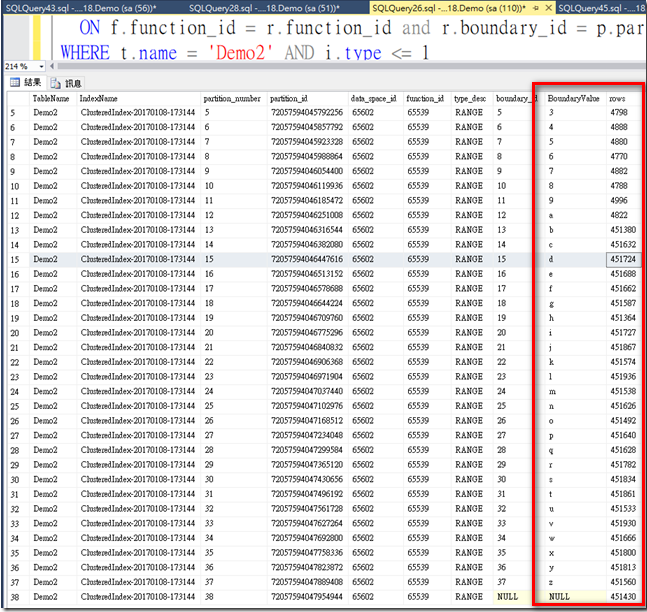
Demo2表分區資料分佈
案例:當利用LIKE做前綴查找
這裡從前述的資訊可以知道在Demo1 a0%最少有6個區需要查找
而Demo2只有一個區需要查找
接下來我們先簡單的看一下兩張表在相同查詢時IO的差異 (可以看到第二張表較優)
接下來我們仔細看一下相關的執行計畫與查找的分區數可以發現在執行時Demo1會查找七個分區,而Demo2只會從一個分區中進行查找
案例:當從預設分區查找
這次我們簡單的查找z開頭的UserID ,從先前的資訊可以知道。
表Demo1並沒有建立z開頭的分區,因此z相關的資料將會存放到預設分區(Null區)
表Demo1的預設分區統計約有643萬筆,而表Demo2的z分區約有45萬筆
由此可見在Demo2表上查找應該會優於Demo1的(當資料筆數再更多時,差異會更大)見下圖
以上便是今天的表分區探討,替各位總結一下。
1.在規劃表分區時,首先要注意該表的相關查詢語句,以最常用在條件式的字段做為分區依據是較佳的。
2.承上,即使使用最常用的字段做為分區依據,仍然要確認資料是否適合做為分區。
例如:即使常用的查詢字段為姓別 (男、女),用此字段做為分區,僅能將資料最多分為三個區。在大資料時,性能並無法顯著的增加。簡單的評估可以用目前的資料筆數除以分區數,可得知每個分區的資料分佈進而做分區建立的評估依據
比如可以用下列這種簡單的語法計算每個分區數
--12228608 / 37 SELECT COUNT(1) / (SELECT COUNT(1) FROM (SELECT 1 as Counts FROM Demo1 GROUP BY SUBSTRING(UserID,1,1)) as X)FROM Demo1
後記
在寫本篇時,還發現了一個需要注意的問題,當利用VARCHAR字段做為分區依據時。
在查詢時需要在該字段使用 LIKE 而不是一般的Equal (=)做為查找。如果採用一般的Equal(=)做為查找時,該執行計畫會顯示查找了所有分區內容具體原因如果有朋友知道,還請協助解答。
以下是查找的比較圖
使用Equal(=)查找
使用LIKE查找
本次用來查詢表分區相關資訊的語法
SELECT t.name AS TableName, i.name AS IndexName, p.partition_number, p.partition_id, i.data_space_id, f.function_id, f.type_desc, r.boundary_id, r.value AS BoundaryValue,p.rowsFROM sys.tables AS t JOIN sys.indexes AS i ON t.object_id = i.object_id JOIN sys.partitions AS p ON i.object_id = p.object_id AND i.index_id = p.index_id JOIN sys.partition_schemes AS s ON i.data_space_id = s.data_space_id JOIN sys.partition_functions AS f ON s.function_id = f.function_id LEFT JOIN sys.partition_range_values AS r ON f.function_id = r.function_id and r.boundary_id = p.partition_number WHERE t.name = '已分區表名稱' AND i.type <= 1 ORDER BY p.partition_number;
最後謝謝各位觀看囉!如果有問題歡迎在底下留言與我討論